Le Hui 惠乐
 |
PhD Student, |
Research
My research interests focus on 3D computer vision, including 3D point cloud processing, 3D scene segmentation, 3D object generation, 3D single object tracking, point cloud based large-scale place recognition, etc. My recent focus is on fully-/semi- supervised 3D feature learning on large-scale point clouds.
Fully-/Semi- supervised 3D scene segmentation
 |
Point cloud semantic segmentation is a crucial task in 3D scene understanding. Due to large amount of irregular and unorder 3D points, how to effecitively learn discriminative point features for segmenting different objects in the 3D scenes is very challenging. Thus, it is necessary to study powerful and effectively point cloud learning network. We develop a new deep iterative clustering network to directly generate superpoints from irregular 3D point clouds in an end-to-end manner. In addition, we propose a semi-supervised semantic point cloud segmentation network, which infers high-quality pseudo labels of unlabeled points from the few annotated 3D points for semantic segmentation. |
3D single object tracking
|
|
3D single object tracking in point clouds is still a challenging problem due to the sparsity of LiDAR points in dynamic environments. We propose a novel Siamese voxel-to-BEV tracker, which aims to improve the tracking performance of 3D single object tracking, especially in sparse point clouds. It consists of a Siamese shape-aware feature learning network and a voxel-to-BEV target localization network. The Siamese shape-aware feature learning network can capture 3D shape information of the object to learn the discriminative features and the voxel-to-BEV target localization network regresses the target’s 2D center and the z-axis center from the dense bird’s eye view feature map in an anchor-free manner. |
3D place recognition
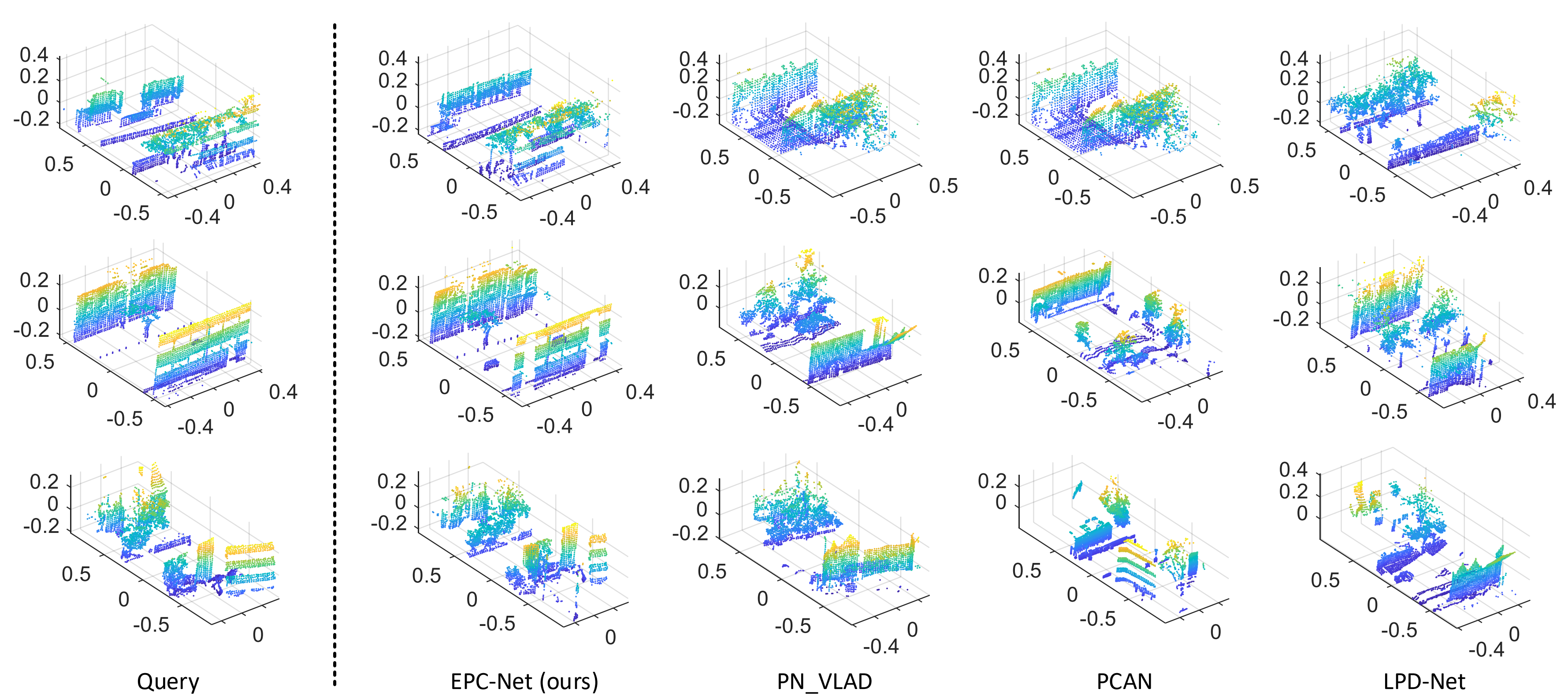 |
Deep learning based point cloud descriptors have achieved impressive results in the place recognition task. Nonetheless, due to the sparsity of point clouds, how to extract discriminative local features of point clouds to efficiently form a global descriptor is still a challenging problem. We propose a pyramid point cloud transformer network to learn the discriminative global descriptors from point clouds for efficient retrieval. What's more, we also develop an efficient point cloud learning network (EPC-Net) to form a global descriptor for visual place recognition, which can obtain good performance and reduce computation memory and inference time. |
3D object generation
 |
We propose an effective point cloud generation method, which can generate multi-resolution point clouds of the same shape from a latent vector. Specifically, we develop a novel progressive deconvolution network with the learning-based bilateral interpolation. The learning-based bilateral interpolation is performed in the spatial and feature spaces of point clouds so that local geometric structure information of point clouds can be exploited. In order to keep the shapes of different resolutions of point clouds consistent, we propose a shape-preserving adversarial loss to train the point cloud deconvolution generation network. |